
Gouvernance de la donnée : quelle méthodologie projet adopter pour réussir un projet de Big Data ?
Temps de lecture 5 minutes
Le Big Data permet de répondre à des besoins métiers en s’appuyant sur le traitement de la donnée. Mais plus les volumes de données transitant chaque jour sur les SI des entreprises sont importants, moins bien ils sont exploités. Pourquoi ? Le plus souvent par manque de stratégie accompagnant ces projets Big Data.
3 difficultés majeures émergent parmi les freins que rencontrent les entreprises lors de la mise en place d’une stratégie Data Driven :
 |
|
Comment faire face à ces difficultés ?
I. Bien définir les objectifs du projet
- Définir un objectif business mesurable. Exemple : optimiser la gestion des stocks et réduire mes coûts d’infrastructure de 30%
- Définir les moyens opérationnels dont on dispose : Quels sont les leviers / Quel est la faisabilité ? Exemple : On dispose d’un entrepôt valorisé, d’un logiciel de suivi des stocks, d’une équipe dédiée, d’un process de gestion. Comment améliorer les process pour atteindre notre objectif business grâce à la data ?
II. Faire la checklist du cadrage
- Définir les interlocuteurs : Métier, IT, Recrutement à prévoir
- Sources de données interne ou externe : Identifier l’architecture actuelle et les flux de données : définir un dictionnaire des données partagé.
- Définir les besoins utilisateurs : être à l’écoute des projets Bottom Up et ne pas imposer un gros projet top down. Les utilisateurs savent faire parler la donnée.
- Faisabilité : Prioriser les POC plutôt que de se lancer dans un gros projet directement pour valoriser l’apport d’un projet data rapidement
- Définir des critères d’acceptation en amont (Go/No Go)
III. Utiliser la méthodologie des 4V pour choisir la solution adaptée
Choisir les bonnes technologies et une architecture adaptée en fonction des réponses à la méthodologie des 4V :
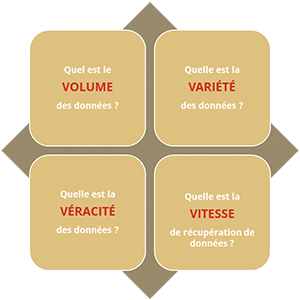
- Quel est le VOLUME de données dont je dispose ? Le volume va contribuer à déterminer l’architecture à mettre en place et les technologies à utiliser. On ne mettra pas en place le même système pour 1Mo de données que pour 10To et on ne choisira pas les mêmes technologies. Pour 1Mo de données on n’utilisera pas forcément Hadoop. (Framework pour la distribution du stockage de données) On ne choisira également pas la même base de données, etc.…
- Quelle est la VARIÉTÉ de mes données ? (Canaux de récupérations des données sources) La variété des données et de ses points de récupérations va également déterminer l’architecture et le choix des technologies. On ne pourra pas mettre en place les même architectures et technologies si l’on a 1 seul point de récupération de données (un capteur) que si l’on en a 100 (boutiques). Il faut que l’architecture soit adaptée à chaque points de récupération des données et leurs formats (xml, csv, database, …)
- Quelle est la VÉRACITÉ de mes données ? Critère d’acceptation Il faut analyser les données afin de déterminer leur véracité. Si nos données contiennent par exemples des sacs à mains qui sont considérés comme « maquillage », la véracité de mes données est faible et il faudra en améliorer la qualité. De même si mes données contiennent beaucoup de doublons.
- Quelle est ma VITESSE de récupération de données ? Faisabilité La vitesse de récupération des données va influer sur le choix des technologies et de l’architecture mais surtout sur la faisabilité du projet, si la vitesse de récupération des données est trop faible, mettre en place un système de Big Data serait inutile. Si l’on récupère 1ko de données par jour, un tel projet ne serait pas réellement utile, en revanche, avec 1mo par seconde, il apporterait énormément.
IV. Mettre en place une méthodologie projet Big Data
- Dataquality – préparation des données : ne pas sous-estimer cette phase du projet On mettra en place la méthodologie de préparation des données, la façon d’en améliorer le plus la qualité. La meilleure façon de les traiter pour avoir le meilleur résultat possible. C’est l’analyse des données en amont qui permet de choisir la méthodologie de préparation la plus adaptée. Nous allons pendant cette phase définir qu’il faut enlever les doublons par exemple. Le métier assistera l’IT pendant cette phase.
- Mise en place d’une organisation projet de type Datalab (PO, Data engineer, Data scientist, Data analyst data stewart, CDO) On mettra en place une organisation projet adaptée, qui comprendra un Datalab qui réunit toutes les personnes autour des données : Product Owner, Data Engineer, Data Scientist, Data Analyst, Data Stewart. Cette ‘unité’ permettra de réunir tous les acteurs de la donnée et de faciliter la communication et la compréhension entre les différents acteurs du projet.
- Analyse en continue des données : inclure le Business avec la Dataviz On mettra en place un système d’analyse en continue des données afin que leur qualité ne diminue pas sur le temps. Tout au long du projet nous inclurons également les acteurs de la partie business afin de leur montrer l’utilité du projet au travers de la datavisualisation par exemple.
En conclusion, adapter sa méthodologie projet est primordial pour réussir son projet Big Data.
Sur le long terme, le succès d’un projet Big Data est également une première étape vers d’autres applications liées à la donnée telle que l’intelligence artificielle par exemple, dont le traitement des données est un enjeu crucial.
Adone Conseil vous accompagne sur l’ensemble de vos projets Data, Big Data et Analytics.
Sources : EBG – Big Data 5 ans après / Sondage San Francisco Partners
Vous Aimerez aussi
-

Actualités
Data Catalog, Data Dictionary, Data Glossary… Quelles différences pour votre stratégie Data ?
- Data Analytics



")